This demo shows how to query metadata from the PDB archive.
This exmaple queries the _citation category. Each category represents a table, and fields represent database columns. Avalible tables and columns
Example data from 100D.cif * _citation.id primary * _citation.title Crystal structure of … * _citation.journal_abbrev ‘Nucleic Acids Res.’ * _citation.journal_volume 22 * _citation.page_first 5466 * _citation.page_last 5476 * _citation.year 1994 * _citation.journal_id_ASTM NARHAD * _citation.country UK * _citation.journal_id_ISSN 0305-1048 * _citation.journal_id_CSD 0389 * _citation.book_publisher ? * _citation.pdbx_database_id_PubMed 7816639 * _citation.pdbx_database_id_DOI 10.1093/nar/22.24.5466
Data are probided through Mine 2 SQL
Queries can be designed with the interactive PDBj Mine 2 query service
In [16]:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from mmtfPyspark.datasets import pdbjMineDataset
import matplotlib.pyplot as plt
In [2]:
spark = SparkSession.builder\
.master("local[*]")\
.appName("PDBMetaDataDemo")\
.getOrCreate()
Query the following fields from the :raw-latex:`citation `category using PDBj’s Mine 2 web service: * journal_abbrev * pdbx_database_id_PubMed * year
In [3]:
sqlQuery = "SELECT pdbid, journal_abbrev, \"pdbx_database_id_PubMed\", year from citation WHERE id = 'primary'"
ds = pdbjMineDataset.get_dataset(sqlQuery)
In [4]:
ds.show(10, False)
+-----------+------------------+-----------------------+----+
|structureId|journal_abbrev |pdbx_database_id_PubMed|year|
+-----------+------------------+-----------------------+----+
|100D |Nucleic Acids Res.|7816639 |1994|
|101D |Biochemistry |7711020 |1995|
|101M |Thesis, Rice |-1 |1999|
|102D |J.Med.Chem. |7608897 |1995|
|102L |Nature |8429913 |1993|
|102M |Thesis, Rice |-1 |1999|
|103D |J.Mol.Biol. |7966337 |1994|
|103L |Nature |8429913 |1993|
|103M |Thesis, Rice |-1 |1999|
|104D |Biochemistry |7857947 |1995|
+-----------+------------------+-----------------------+----+
only showing top 10 rows
Published entires contain the word “published” in various upper/lower case combinations
In [5]:
ds = ds.filter("UPPER(journal_abbrev) NOT LIKE '%PUBLISHED%'")
In [9]:
ds.groupBy("journal_abbrev").count().sort(col("count").desc()).show(10,False)
+------------------------+-----+
|journal_abbrev |count|
+------------------------+-----+
|J.Biol.Chem. |10479|
|J.Mol.Biol. |10311|
|Biochemistry |9877 |
|Proc.Natl.Acad.Sci.USA |5633 |
|Structure |5191 |
|Acta Crystallogr.,Sect.D|4253 |
|J.Med.Chem. |3871 |
|Nature |3263 |
|Nat Commun |2519 |
|Protein Sci. |2374 |
+------------------------+-----+
only showing top 10 rows
-1 if PubMed Id is not available
In [10]:
ds = ds.filter("pdbx_database_id_PubMed > 0")
print(f"Entires with PubMed Ids: {ds.count()}")
Entires with PubMed Ids: 113405
In [14]:
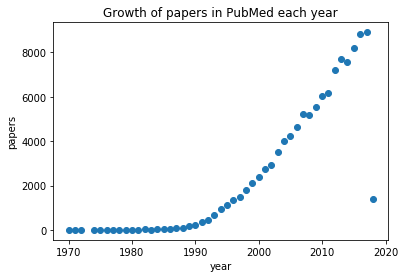
print("PubMed Ids per year: ")
idsPerYear = ds.groupBy("year").count().sort(col("year").desc())
idsPerYear.show(10, False)
PubMed Ids per year:
+----+-----+
|year|count|
+----+-----+
|2018|1386 |
|2017|8907 |
|2016|8806 |
|2015|8187 |
|2014|7556 |
|2013|7693 |
|2012|7197 |
|2011|6178 |
|2010|6040 |
|2009|5522 |
+----+-----+
only showing top 10 rows
In [21]:
# Get year and publications as list
year = idsPerYear.select("year").collect()
publications = idsPerYear.select("count").collect()
# Make scatter plot with matplotlib
plt.scatter(year, publications)
plt.xlabel("year")
plt.ylabel("papers")
plt.title("Growth of papers in PubMed each year")
Out[21]:
Text(0.5,1,'Growth of papers in PubMed each year')
In [23]:
spark.stop()
